
Dogs and cats clssification
Cats and dogs images classification
In this project, we will classify the images of dogs and cats using CNN models.
Preparation
Import all the modules we need.
import os
from tensorflow.keras import utils
from tensorflow.keras import layers
from tensorflow import keras
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
Import the dataset.
# location of data
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
# download the data and extract it
path_to_zip = utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
# construct paths
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
# parameters for datasets
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
# construct train and validation datasets
train_dataset = utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
# construct the test dataset by taking every 5th observation out of the validation dataset
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
68608000/68606236 [==============================] - 2s 0us/step
68616192/68606236 [==============================] - 2s 0us/step
Found 2000 files belonging to 2 classes.
Found 1000 files belonging to 2 classes.
Create a visualiation function to view the data briefly.
def dataset_visualiztion(dataset):
class_names = dataset.class_names
plt.figure(figsize=(12, 8))
p = np.random.randint(1, 20)
for images, labels in train_dataset.take(p):
for i in range(6):
ax = plt.subplot(2, 3, i + 1)
if i <= 2:
plt.imshow(images[labels==0][i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
else:
plt.imshow(images[labels==1][i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
dataset_visualiztion(train_dataset)
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:7: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.
import sys

Prefetch the dataset.
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Use a lable iterator to count the numbers of cats and dogs images.
labels_iterator= train_dataset.unbatch().map(lambda image, label: label).as_numpy_iterator()
cat_num = 0
dog_num = 0
for i in labels_iterator:
if i == 0:
cat_num += 1
elif i == 1:
dog_num += 1
cat_num,dog_num
(1000, 1000)
We can see that we have an equal number of cat and dogs images, which serve as the baseline 50 percent.
Model1
Use the keras module to construct a model, with 2 Conv2d layers, two MaxPooling2D layers, one Flatten layer, one Dense layer, and a Dropout layer
model1 = keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(160, 160, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dropout(0.2),
layers.Dense(2)
])
model1.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 158, 158, 32) 896
max_pooling2d (MaxPooling2D (None, 79, 79, 32) 0
)
conv2d_1 (Conv2D) (None, 77, 77, 32) 9248
max_pooling2d_1 (MaxPooling (None, 38, 38, 32) 0
2D)
flatten (Flatten) (None, 46208) 0
dropout (Dropout) (None, 46208) 0
dense (Dense) (None, 2) 92418
=================================================================
Total params: 102,562
Trainable params: 102,562
Non-trainable params: 0
_________________________________________________________________
model1.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history = model1.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 16s 80ms/step - loss: 37.9397 - accuracy: 0.4995 - val_loss: 0.7093 - val_accuracy: 0.5000
Epoch 2/20
63/63 [==============================] - 5s 80ms/step - loss: 0.6534 - accuracy: 0.5870 - val_loss: 0.7127 - val_accuracy: 0.5309
Epoch 3/20
63/63 [==============================] - 5s 73ms/step - loss: 0.6151 - accuracy: 0.6450 - val_loss: 0.7786 - val_accuracy: 0.5111
Epoch 4/20
63/63 [==============================] - 5s 74ms/step - loss: 0.5569 - accuracy: 0.6885 - val_loss: 0.7931 - val_accuracy: 0.5285
Epoch 5/20
63/63 [==============================] - 6s 95ms/step - loss: 0.4586 - accuracy: 0.7740 - val_loss: 0.9013 - val_accuracy: 0.5334
Epoch 6/20
63/63 [==============================] - 5s 77ms/step - loss: 0.3916 - accuracy: 0.8155 - val_loss: 1.0219 - val_accuracy: 0.5396
Epoch 7/20
63/63 [==============================] - 5s 76ms/step - loss: 0.3455 - accuracy: 0.8395 - val_loss: 1.2504 - val_accuracy: 0.5309
Epoch 8/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3146 - accuracy: 0.8570 - val_loss: 1.1257 - val_accuracy: 0.5285
Epoch 9/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3152 - accuracy: 0.8585 - val_loss: 1.5763 - val_accuracy: 0.5161
Epoch 10/20
63/63 [==============================] - 5s 76ms/step - loss: 0.2458 - accuracy: 0.9005 - val_loss: 1.8339 - val_accuracy: 0.5285
Epoch 11/20
63/63 [==============================] - 5s 75ms/step - loss: 0.2658 - accuracy: 0.8835 - val_loss: 1.4967 - val_accuracy: 0.5285
Epoch 12/20
63/63 [==============================] - 5s 74ms/step - loss: 0.2391 - accuracy: 0.9025 - val_loss: 1.7440 - val_accuracy: 0.5359
Epoch 13/20
63/63 [==============================] - 5s 76ms/step - loss: 0.1920 - accuracy: 0.9160 - val_loss: 2.1691 - val_accuracy: 0.5309
Epoch 14/20
63/63 [==============================] - 7s 103ms/step - loss: 0.2078 - accuracy: 0.9265 - val_loss: 2.2219 - val_accuracy: 0.5656
Epoch 15/20
63/63 [==============================] - 7s 103ms/step - loss: 0.1857 - accuracy: 0.9255 - val_loss: 2.4003 - val_accuracy: 0.5421
Epoch 16/20
63/63 [==============================] - 5s 76ms/step - loss: 0.1590 - accuracy: 0.9375 - val_loss: 2.5429 - val_accuracy: 0.5359
Epoch 17/20
63/63 [==============================] - 6s 83ms/step - loss: 0.1371 - accuracy: 0.9450 - val_loss: 2.9518 - val_accuracy: 0.5557
Epoch 18/20
63/63 [==============================] - 5s 78ms/step - loss: 0.1627 - accuracy: 0.9395 - val_loss: 2.5612 - val_accuracy: 0.5470
Epoch 19/20
63/63 [==============================] - 7s 104ms/step - loss: 0.1702 - accuracy: 0.9380 - val_loss: 2.5409 - val_accuracy: 0.5545
Epoch 20/20
63/63 [==============================] - 7s 110ms/step - loss: 0.1559 - accuracy: 0.9475 - val_loss: 2.9493 - val_accuracy: 0.5384
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
<matplotlib.legend.Legend at 0x7fa3eb1dffd0>
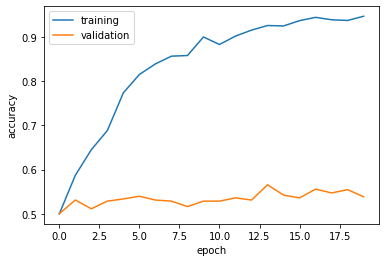
Observation1: the accuracy of model1 stabilized between 50% and 55% during training
Observation2: the baseline is 50 percent, which I do 5 percent better.
Observation3: overfitting is observed since the training accuracy is way more higher.
Model2
Based on model1, we add data augmentation to the model, which is randomflip and randomrotation.
First demonstrate the randomflip and randomrotation
## create original image
for images,labels in train_dataset.take(1):
example = images[1]
plt.imshow(example.numpy().astype("uint8"))
plt.axis("off")

## Create flipped image
flip = layers.RandomFlip()
example_flipped = flip(example,training = True)
plt.imshow(example_flipped.numpy().astype("uint8"))
plt.axis("off")
(-0.5, 159.5, 159.5, -0.5)

## Create rotated image with parameter 0.1
rotate1 = layers.RandomRotation(0.1)
example_rotated1 = rotate1(example, training = True)
plt.imshow(example_rotated1.numpy().astype("uint8"))
plt.axis("off")
(-0.5, 159.5, 159.5, -0.5)

## Create rotated image with parameter 0.2
rotate2 = layers.RandomRotation(0.2)
example_rotated2 = rotate1(example, training = True)
plt.imshow(example_rotated2.numpy().astype("uint8"))
plt.axis("off")
(-0.5, 159.5, 159.5, -0.5)

Constrcut the model2, which adds the randomfilp and randomroation layer to model1
model2 = keras.Sequential([
layers.RandomFlip(),
layers.RandomRotation(0.1),
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(160, 160, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Dropout(0.2),
layers.Dense(64),
layers.Flatten(),
layers.Dense(2)
])
model2.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history2 = model2.fit(train_dataset,
epochs=20,
validation_data = validation_dataset
)
Epoch 1/20
63/63 [==============================] - 7s 81ms/step - loss: 94.0362 - accuracy: 0.4980 - val_loss: 1.0434 - val_accuracy: 0.5569
Epoch 2/20
63/63 [==============================] - 5s 82ms/step - loss: 0.8790 - accuracy: 0.5585 - val_loss: 0.8621 - val_accuracy: 0.5309
Epoch 3/20
63/63 [==============================] - 5s 82ms/step - loss: 0.7703 - accuracy: 0.5730 - val_loss: 0.8222 - val_accuracy: 0.5557
Epoch 4/20
63/63 [==============================] - 5s 80ms/step - loss: 0.7476 - accuracy: 0.5540 - val_loss: 0.7581 - val_accuracy: 0.5470
Epoch 5/20
63/63 [==============================] - 7s 114ms/step - loss: 0.7149 - accuracy: 0.5550 - val_loss: 0.7190 - val_accuracy: 0.5136
Epoch 6/20
63/63 [==============================] - 6s 83ms/step - loss: 0.7148 - accuracy: 0.5440 - val_loss: 0.7369 - val_accuracy: 0.5161
Epoch 7/20
63/63 [==============================] - 7s 100ms/step - loss: 0.7039 - accuracy: 0.5390 - val_loss: 0.7173 - val_accuracy: 0.5210
Epoch 8/20
63/63 [==============================] - 6s 91ms/step - loss: 0.6932 - accuracy: 0.5535 - val_loss: 0.6972 - val_accuracy: 0.5099
Epoch 9/20
63/63 [==============================] - 5s 79ms/step - loss: 0.6958 - accuracy: 0.5415 - val_loss: 0.7237 - val_accuracy: 0.4950
Epoch 10/20
63/63 [==============================] - 6s 88ms/step - loss: 0.6825 - accuracy: 0.5625 - val_loss: 0.7103 - val_accuracy: 0.5248
Epoch 11/20
63/63 [==============================] - 6s 87ms/step - loss: 0.6792 - accuracy: 0.5530 - val_loss: 0.6906 - val_accuracy: 0.5458
Epoch 12/20
63/63 [==============================] - 6s 85ms/step - loss: 0.6733 - accuracy: 0.5765 - val_loss: 0.7388 - val_accuracy: 0.5470
Epoch 13/20
63/63 [==============================] - 5s 79ms/step - loss: 0.6939 - accuracy: 0.5605 - val_loss: 0.6990 - val_accuracy: 0.5235
Epoch 14/20
63/63 [==============================] - 7s 114ms/step - loss: 0.6786 - accuracy: 0.5785 - val_loss: 0.6981 - val_accuracy: 0.5569
Epoch 15/20
63/63 [==============================] - 7s 96ms/step - loss: 0.6727 - accuracy: 0.6135 - val_loss: 0.6915 - val_accuracy: 0.5631
Epoch 16/20
63/63 [==============================] - 6s 85ms/step - loss: 0.6625 - accuracy: 0.6085 - val_loss: 0.7103 - val_accuracy: 0.5644
Epoch 17/20
63/63 [==============================] - 5s 78ms/step - loss: 0.6667 - accuracy: 0.6185 - val_loss: 0.6810 - val_accuracy: 0.5916
Epoch 18/20
63/63 [==============================] - 5s 79ms/step - loss: 0.6750 - accuracy: 0.5965 - val_loss: 0.6808 - val_accuracy: 0.5780
Epoch 19/20
63/63 [==============================] - 5s 79ms/step - loss: 0.6609 - accuracy: 0.6185 - val_loss: 0.6711 - val_accuracy: 0.5817
Epoch 20/20
63/63 [==============================] - 5s 78ms/step - loss: 0.6585 - accuracy: 0.6140 - val_loss: 0.7192 - val_accuracy: 0.5879
plt.plot(history2.history["accuracy"], label = "training")
plt.plot(history2.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
<matplotlib.legend.Legend at 0x7fa462d00810>
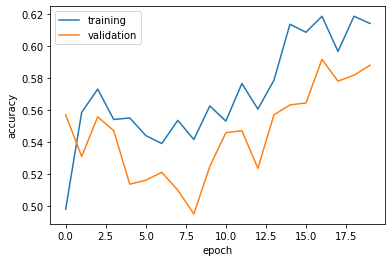
Observation1: the accuracy of model2 stabilized between 55% and 60% during training
Observation2: the accuracy is higher than the first model.
Observation3: overfitting is not observed.
Model3
Create a model with data preprocessing, which adds the prepocessor to the model 2.
i = tf.keras.Input(shape=(160, 160, 3))
x = tf.keras.applications.mobilenet_v2.preprocess_input(i)
preprocessor = tf.keras.Model(inputs = [i], outputs = [x])
model3 = keras.Sequential([
preprocessor,
layers.RandomFlip(),
layers.RandomRotation(0.2),
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(160, 160, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.AveragePooling2D((2,2)),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(2)
])
model3.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history3 = model3.fit(train_dataset,
epochs=20,
validation_data = validation_dataset
)
Epoch 1/20
63/63 [==============================] - 7s 81ms/step - loss: 0.6983 - accuracy: 0.5245 - val_loss: 0.6876 - val_accuracy: 0.5037
Epoch 2/20
63/63 [==============================] - 5s 79ms/step - loss: 0.6738 - accuracy: 0.5630 - val_loss: 0.6384 - val_accuracy: 0.6089
Epoch 3/20
63/63 [==============================] - 5s 80ms/step - loss: 0.6554 - accuracy: 0.5945 - val_loss: 0.6457 - val_accuracy: 0.6238
Epoch 4/20
63/63 [==============================] - 6s 96ms/step - loss: 0.6363 - accuracy: 0.6265 - val_loss: 0.6156 - val_accuracy: 0.6770
Epoch 5/20
63/63 [==============================] - 5s 81ms/step - loss: 0.6279 - accuracy: 0.6460 - val_loss: 0.6250 - val_accuracy: 0.6485
Epoch 6/20
63/63 [==============================] - 5s 81ms/step - loss: 0.6083 - accuracy: 0.6630 - val_loss: 0.6078 - val_accuracy: 0.6621
Epoch 7/20
63/63 [==============================] - 6s 85ms/step - loss: 0.5964 - accuracy: 0.6780 - val_loss: 0.5864 - val_accuracy: 0.6881
Epoch 8/20
63/63 [==============================] - 5s 81ms/step - loss: 0.5845 - accuracy: 0.6935 - val_loss: 0.5811 - val_accuracy: 0.6819
Epoch 9/20
63/63 [==============================] - 5s 79ms/step - loss: 0.5859 - accuracy: 0.6885 - val_loss: 0.6173 - val_accuracy: 0.6559
Epoch 10/20
63/63 [==============================] - 6s 83ms/step - loss: 0.5667 - accuracy: 0.7040 - val_loss: 0.5773 - val_accuracy: 0.6770
Epoch 11/20
63/63 [==============================] - 5s 82ms/step - loss: 0.5689 - accuracy: 0.7175 - val_loss: 0.5646 - val_accuracy: 0.7030
Epoch 12/20
63/63 [==============================] - 5s 79ms/step - loss: 0.5556 - accuracy: 0.7085 - val_loss: 0.5588 - val_accuracy: 0.7203
Epoch 13/20
63/63 [==============================] - 6s 83ms/step - loss: 0.5567 - accuracy: 0.7245 - val_loss: 0.5514 - val_accuracy: 0.7079
Epoch 14/20
63/63 [==============================] - 7s 105ms/step - loss: 0.5342 - accuracy: 0.7275 - val_loss: 0.5286 - val_accuracy: 0.7327
Epoch 15/20
63/63 [==============================] - 7s 100ms/step - loss: 0.5370 - accuracy: 0.7375 - val_loss: 0.5523 - val_accuracy: 0.7215
Epoch 16/20
63/63 [==============================] - 5s 82ms/step - loss: 0.5428 - accuracy: 0.7200 - val_loss: 0.5379 - val_accuracy: 0.7191
Epoch 17/20
63/63 [==============================] - 5s 82ms/step - loss: 0.5231 - accuracy: 0.7360 - val_loss: 0.5801 - val_accuracy: 0.7228
Epoch 18/20
63/63 [==============================] - 5s 80ms/step - loss: 0.5456 - accuracy: 0.7200 - val_loss: 0.5276 - val_accuracy: 0.7277
Epoch 19/20
63/63 [==============================] - 5s 79ms/step - loss: 0.5237 - accuracy: 0.7420 - val_loss: 0.5515 - val_accuracy: 0.7166
Epoch 20/20
63/63 [==============================] - 6s 82ms/step - loss: 0.5189 - accuracy: 0.7465 - val_loss: 0.5612 - val_accuracy: 0.7092
plt.plot(history3.history["accuracy"], label = "training")
plt.plot(history3.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
<matplotlib.legend.Legend at 0x7fa461815990>
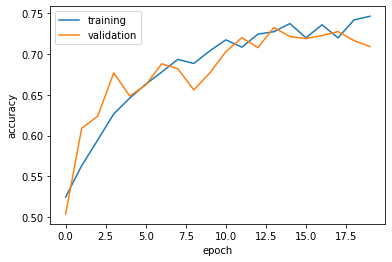
Observation1: the accuracy of model3 stabilized between 70% and 75% during training
Observation2: the accuracy is much higher than the first model.
Observation3: overfitting is not observed.
Model4
Create a model with transfer learning, which has a preprocessor layer, randomflip and randomrotation layer, base model layer, a MaxPooling2D layer, a dropout layer and a dense layer.
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
base_model.trainable = False
i = tf.keras.Input(shape=IMG_SHAPE)
x = base_model(i, training = False)
base_model_layer = tf.keras.Model(inputs = [i], outputs = [x])
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5
9412608/9406464 [==============================] - 0s 0us/step
9420800/9406464 [==============================] - 0s 0us/step
model4 = keras.Sequential([
preprocessor,
layers.RandomFlip(),
layers.RandomRotation(0.2),
base_model_layer,
layers.GlobalMaxPooling2D(),
layers.Dropout(0.2),
layers.Dense(2)
])
model4.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model (Functional) (None, 160, 160, 3) 0
random_flip_3 (RandomFlip) (None, 160, 160, 3) 0
random_rotation_4 (RandomRo (None, 160, 160, 3) 0
tation)
model_1 (Functional) (None, 5, 5, 1280) 2257984
global_max_pooling2d (Globa (None, 1280) 0
lMaxPooling2D)
dropout_3 (Dropout) (None, 1280) 0
dense_4 (Dense) (None, 2) 2562
=================================================================
Total params: 2,260,546
Trainable params: 2,562
Non-trainable params: 2,257,984
_________________________________________________________________
There are more than 2 million parameters to train in this model.
model4.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history4 = model4.fit(train_dataset,
epochs=20, # how many rounds of training to do
validation_data = validation_dataset
)
Epoch 1/20
63/63 [==============================] - 11s 114ms/step - loss: 1.0712 - accuracy: 0.7495 - val_loss: 0.1669 - val_accuracy: 0.9517
Epoch 2/20
63/63 [==============================] - 6s 86ms/step - loss: 0.5815 - accuracy: 0.8620 - val_loss: 0.1806 - val_accuracy: 0.9505
Epoch 3/20
63/63 [==============================] - 6s 87ms/step - loss: 0.5446 - accuracy: 0.8710 - val_loss: 0.1217 - val_accuracy: 0.9653
Epoch 4/20
63/63 [==============================] - 6s 91ms/step - loss: 0.4574 - accuracy: 0.8765 - val_loss: 0.0946 - val_accuracy: 0.9666
Epoch 5/20
63/63 [==============================] - 6s 86ms/step - loss: 0.4618 - accuracy: 0.8770 - val_loss: 0.0819 - val_accuracy: 0.9678
Epoch 6/20
63/63 [==============================] - 6s 86ms/step - loss: 0.4185 - accuracy: 0.8915 - val_loss: 0.1171 - val_accuracy: 0.9641
Epoch 7/20
63/63 [==============================] - 6s 95ms/step - loss: 0.3888 - accuracy: 0.8975 - val_loss: 0.1170 - val_accuracy: 0.9604
Epoch 8/20
63/63 [==============================] - 6s 86ms/step - loss: 0.3261 - accuracy: 0.9070 - val_loss: 0.0920 - val_accuracy: 0.9678
Epoch 9/20
63/63 [==============================] - 6s 85ms/step - loss: 0.3155 - accuracy: 0.9040 - val_loss: 0.0977 - val_accuracy: 0.9678
Epoch 10/20
63/63 [==============================] - 6s 85ms/step - loss: 0.4348 - accuracy: 0.8950 - val_loss: 0.0996 - val_accuracy: 0.9715
Epoch 11/20
63/63 [==============================] - 7s 113ms/step - loss: 0.3441 - accuracy: 0.9045 - val_loss: 0.0944 - val_accuracy: 0.9703
Epoch 12/20
63/63 [==============================] - 7s 104ms/step - loss: 0.3333 - accuracy: 0.9020 - val_loss: 0.0949 - val_accuracy: 0.9703
Epoch 13/20
63/63 [==============================] - 6s 86ms/step - loss: 0.3104 - accuracy: 0.9175 - val_loss: 0.1328 - val_accuracy: 0.9629
Epoch 14/20
63/63 [==============================] - 6s 86ms/step - loss: 0.3602 - accuracy: 0.8975 - val_loss: 0.1444 - val_accuracy: 0.9592
Epoch 15/20
63/63 [==============================] - 6s 87ms/step - loss: 0.3316 - accuracy: 0.9040 - val_loss: 0.0859 - val_accuracy: 0.9691
Epoch 16/20
63/63 [==============================] - 6s 86ms/step - loss: 0.3116 - accuracy: 0.9080 - val_loss: 0.1467 - val_accuracy: 0.9604
Epoch 17/20
63/63 [==============================] - 6s 87ms/step - loss: 0.3474 - accuracy: 0.9055 - val_loss: 0.1720 - val_accuracy: 0.9542
Epoch 18/20
63/63 [==============================] - 6s 87ms/step - loss: 0.3398 - accuracy: 0.9055 - val_loss: 0.1144 - val_accuracy: 0.9691
Epoch 19/20
63/63 [==============================] - 6s 86ms/step - loss: 0.2926 - accuracy: 0.9155 - val_loss: 0.0865 - val_accuracy: 0.9728
Epoch 20/20
63/63 [==============================] - 6s 86ms/step - loss: 0.2808 - accuracy: 0.9140 - val_loss: 0.0765 - val_accuracy: 0.9715
plt.plot(history4.history["accuracy"], label = "training")
plt.plot(history4.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
<matplotlib.legend.Legend at 0x7fa4e0846f90>
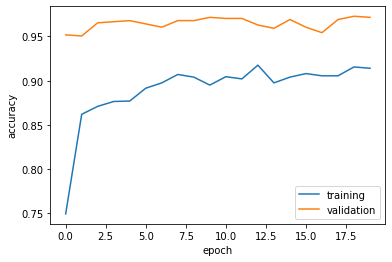
Observation1: the accuracy of model3 stabilized at 90% to 95% during training
Observation2: the accuracy is much higher than the first model.
Observation3: overfitting is observed.
Test model4
Model4 has the highest accuracy, we apply the model to the test_dataset.
model4.evaluate(test_dataset)
6/6 [==============================] - 1s 54ms/step - loss: 0.0896 - accuracy: 0.9583
[0.08964353799819946, 0.9583333134651184]
We have an accuracy of 95 percent!